



Today’s AI landscape is characterized by a gap. While it is often relatively easy to reach the proof of concept (PoC) stage, getting from a PoC to a reliable production system is often much more challenging than teams expect. As a result, by some industry estimates, nearly 80% of enterprise AI projects never make it out of the lab.
The problem isn’t a data quality or infrastructure issue, but rather a architectural positioning one. If teams over-engineer complex models before knowing what can go wrong in production, they are creating more problems to solve, while increasing the total cost of ownership (TCO) of the production environment in the process.
Why do AI projects stall in production – despite often being well-designed and well-funded?
1. The fine-tuning trap
Many organizations assume that to solve a specialized business problem, they must fine-tune an LLM on their own data. Yet, contrary to conventional wisdom, this need to custom train is overblown and fraught with technical debt. While a fine-tuned model can capture a static snapshot, when your underlying business logic or data schema changes, it turns into an expensive legacy model that you cannot easily fix and must instead completely retrain.
2. The reliability paradox
While 90% accuracy is considered excellent in a lab, it’s a disaster in real life. In a production environment – a high‑stakes setting serving millions of interactions – a 10% failure rate is a catastrophe. The model lacks any mechanism that can rein in its response with real-time, verifiable facts. Put simply, it doesn’t know if what it’s saying is true or false.
3. The TCO benchmark: the $1.00 vs. $0.05 economic gap
Initial performance numbers are seductive, but TCO tells a different story. Most fine-tuning projects fail because the maintenance phase becomes prohibitively expensive, but that’s not all. Let’s see how it compares to the other solutions: prompt engineering and retrieval-augmented generation (RAG).
| Feature | Prompt Engineering / RAG | Fine-Tuning |
| Setup Time | Days to Weeks | Months |
| Data Required | Minimal (Few-shot examples) | High (Thousands of labeled rows) |
| Inference Cost | Higher (per token) | Lower (on smaller models) |
| Maintenance | Low (Update the prompt/database) | High (Periodic re-training) |
| Reliability | Traceable (via citations) | “Black Box” behavior |
There’s one major standout here. Prompt engineering can be implemented in days, and even RAG – which is slightly more difficult – typically only takes from days to a few weeks. Fine-tuning, on the other hand, takes months! Also, RAG can still be useful with minimal curated data, whereas fine-tuning relies on thousands of labeled rows.
The one area where fine-tuning does win is cost of AI inference. Since a fine-tuned LLM is smaller and more specialized, it can be cheaper to serve per query, which explains why teams concerned with ‘serving’ costs prefer it. However, the financial overhead of ongoing maintenance eventually creeps back into the picture, so the initial cost advantage disappears over time.
An unexpected stall in production also can result in an architectural pivot. Here are some real-world examples of exactly this happening.
Real-world scenario A: enterprise customer support assistant
A large technology company builds an AI assistant to answer customer support questions. During the proof-of-concept phase, the team fine-tunes a language model using thousands of historical chat transcripts and internal troubleshooting guides, achieving impressive evaluation scores and strong demo performance.
However, once deployed, the system begins to fail quietly. Product policies change, new devices launch, and support procedures evolve every few weeks, but the fine-tuned model continues generating answers based on outdated information embedded in its training data. Updating the system now requires collecting new labeled data and retraining the model – a process that takes weeks, at a significant cost.
Eventually, engineers replace the approach with a retrieval-based system that pulls responses from live documentation, allowing updates to happen instantly without retraining. The project succeeds only after shifting from optimizing model intelligence to optimizing adaptability.
Real-world scenario B: AI contract analysis in financial services
A financial institution deploys an AI system to review legal contracts and extract risk clauses. Early experiments show that a fine-tuned model performs well and offers lower per-query inference costs compared to larger general models, convincing leadership to move forward. In production, however, the hidden complexity emerges: regulations change, contract templates vary by region, and legal language evolves constantly.
Each update requires new annotations from expensive domain experts and repeated retraining cycles, while engineers struggle to explain inconsistent outputs to compliance teams. Maintenance costs quickly exceed the expected savings, and reliability concerns slow adoption. The organization ultimately transitions to an RAG approach that references up-to-date policy documents and provides traceable citations, reducing operational overhead and restoring stakeholder trust.
There’s one key takeaway here: the real cost of AI systems is not running them once, but keeping them correct over time.
Simple Talk is brought to you by Redgate Software
The solution: the ‘70% rule’ and RAG-first architectures
In my professional work, the 70% rule has been the remedy for most of our production roadblocks. Essentially, around 70% of production-grade AI applications will be more reliable and cost less with RAG and sophisticated prompting rather than through fine-tuning.
Why is RAG better than AI fine-tuning in production?
In more detail, RAG is the better option because of a few reasons:
Traceability: RAG serves as an ‘open book’ model that tells you exactly where it gets its information.
Agility: You can update your data in a vector database in seconds. The system doesn’t require you to retrain the LLM to apply changes.
Predictability: By keeping the model weights that govern the LLM’s core (pre-update) behavior frozen, we can 1) ensure the model doesn’t suddenly worsen, and 2) prevent the model from catastrophically forgetting.
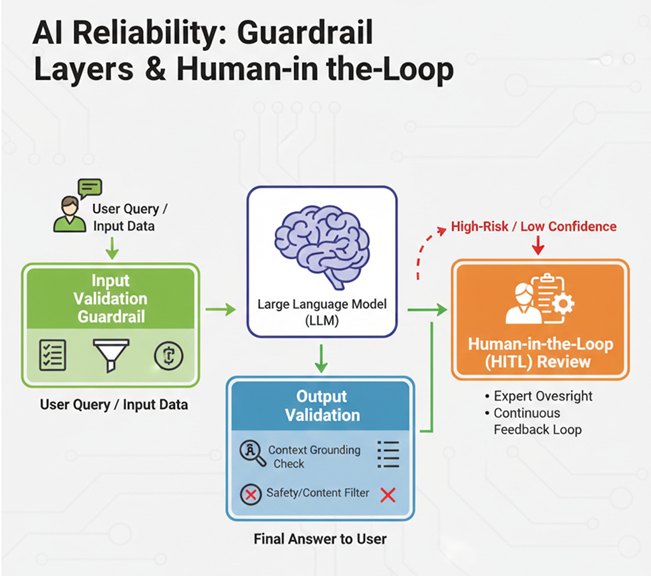
Explaining prescriptive guardrails and human-in-the-loop
The final bridge from lab to production is the guardrail layer. These are secondary checks in which your inputs and outputs are vetted against your particular business constraints.
Using scoring mechanisms such as the Sequential Probability Ratio Test (SPRT), the system can automatically flag low-confidence interactions but still pass them to a human expert in a human-in-the-loop (HITL) workflow. This process includes:
Anomaly detection: An SPRT model will track the cumulative log-likelihood ratio of an incoming data stream from a baseline to indicate that data as anomalous if the ratio crosses a pre-defined threshold.
Automated escalation: Although the score is likely to bounce around near the edge of the highest threshold, crossing the threshold should produce a “code blue” alert for immediate, documented, manual review.
Filtering: The framework will filter out the “known-goods” and allow experts to hone in on high-risk edge cases. This could save more than 10,000 man-hours in some high-volume environments.
Summary
Rather than seeking perfection, the 70% rule is based on the law of diminishing returns. In real-world deployments, a system using RAG that achieves 95% reliability at five cents a query is preferable to a fine-tuned system that achieves 96% reliability but costs $1.00 a query (or more) in infrastructure, specialized talent, care and feeding.
So, before you commit to months of fine-tuning, ask your team if you’ve really found the limits of RAG and your prescriptive guardrails. Simplicity is often the best course of action.
FAQs: AI in production
1. Why do so many AI projects fail to reach production?
Many teams reach a proof of concept quickly but struggle with reliability, maintenance, and architecture challenges. As a result, up to 80% of enterprise AI projects never move beyond experimentation.
2. What is the “fine-tuning trap”?
Fine-tuning can create models that quickly become outdated when business rules or data change, requiring expensive retraining and ongoing maintenance.
3. Why isn’t 90% AI accuracy enough in production?
At scale, a 10% failure rate can cause serious issues. Production systems need stronger reliability, validation, and fact-checking mechanisms.
4. What is RAG in AI?
Retrieval-Augmented Generation (RAG) combines a language model with real-time data retrieval, allowing responses to be based on current and verifiable information.
5. Why is RAG often better than fine-tuning?
RAG is more adaptable. You can update data instantly without retraining the model, making it easier and cheaper to maintain in production.
6. What is the “70% rule” for AI systems?
Roughly 70% of production AI applications work better with RAG and prompt engineering rather than fine-tuning.
7. What are AI guardrails?
AI guardrails are validation layers that check inputs and outputs, detect anomalies, and escalate uncertain cases to humans.
8. What is the key lesson for enterprise AI?
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved

Load comments